
Comparing GenAI LLMs for database tuning
SQL tuning remains a critical task for improving database performance, and with the emergence of Generative AI LLMs (Large Language Models), there’s a fresh perspective on optimising queries. In this article, we’ll explore how various AI language models measure up in the world of SQL tuning.
As database workloads become more complex, traditional tuning methods can struggle to keep up. Gen-AI LLMs offer an exciting alternative, leveraging natural language understanding to suggest performance improvements and query optimisations. Today, we’ll dive into a comparative analysis of a few leading LLMs and see how they fare in real-world SQL tuning scenario. The LLMs covered in this test were:
- Microsoft Copilot
- OpenAI GPT-4o
- Google Gemini
- Deepseek
- Granite
- Perplexity
Testing Methodology
The testing methodology, while not scientific, used a slow SQL query which was doing a full table scan on a large table. A full table scan means it has to scan every record in the table which is inefficient compared to using an index to find the rows that the query needs. Lacking the appropriate indexes is one of the most common reasons for slow database performance which is the reason I opted for this test scenario.
The number one answer I was looking for here was a combined index on multiple columns in the WHERE clause of the SQL. I had already tested this index and seen that the query response time went from 1m14s to 6.23ms which is 11,878 times faster or a reduction of 99.99% in resource usage for the query.
There are other suggestion I might expect such as:
- Query Rewriting
- Updating the statistic on the tables
- Table partitioning
- Materialized views
- Parallel query
- DB Parameter tuning
These could all be valid in other cases but in this case, none of these would give the 99.99% reduction in resource usage that the combined index above gives.
Here is the inefficient query used for the test:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
SELECT
rates.description,
COUNT(vendor_id) AS num_trips,
AVG(total_amount) AS avg_total,
AVG(tip_amount) AS avg_tip,
MIN(trip_distance) AS min_distance,
AVG (trip_distance) AS avg_distance,
MAX(trip_distance) AS max_distance,
AVG(passenger_count) AS avg_passengers
FROM
rides
JOIN rates ON rides.rate_code = rates.rate_code
WHERE
pickup_datetime > to_timestamp('2016-01-06 09:00:00', 'YYYY-MM-DD HH24:MI:SS')
AND pickup_datetime <= to_timestamp('2016-01-06 10:00:00', 'YYYY-MM-DD HH24:MI:SS')
AND passenger_count = 2
GROUP BY
rates.description
ORDER BY
rates.description
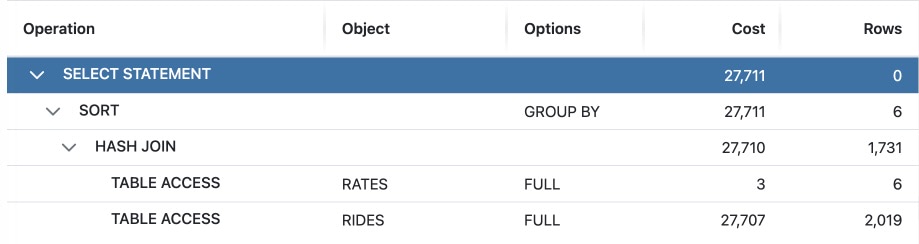
And here is it’s execution plan shown in DBmarlin. You can see the FULL TABLE ACCESS on RIDES table has a high cost of 27,707 since RIDES is a large table with 11 million rows in this case.
The prompt we sent to the different LLMs looked like this and contains the DB technology, the SQL statement and the execution plan in JSON format.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
I have a sql statement for oracle: SELECT
rates.description,
COUNT(vendor_id) AS num_trips,
AVG(total_amount) AS avg_total,
AVG(tip_amount) AS avg_tip,
MIN(trip_distance) AS min_distance,
AVG (trip_distance) AS avg_distance,
MAX(trip_distance) AS max_distance,
AVG(passenger_count) AS avg_passengers
FROM
rides
JOIN rates ON rides.rate_code = rates.rate_code
WHERE
pickup_datetime > to_timestamp('2016-01-06 09:00:00', 'YYYY-MM-DD HH24:MI:SS')
AND pickup_datetime <= to_timestamp('2016-01-06 10:00:00', 'YYYY-MM-DD HH24:MI:SS')
AND passenger_count = 2
GROUP BY
rates.description
ORDER BY
rates.description,
With execution plan: [{"child_number":1,"id":0,"parent_id":0,"depth":0,"cost":829,"operation":"SELECT STATEMENT","cardinality":0,"bytes":0,"optimizer":"ALL_ROWS"},{"child_number":1,"id":1,"parent_id":0,"depth":1,"cost":829,"operation":"SORT","options":"GROUP BY","cardinality":6,"bytes":264},{"child_number":1,"id":2,"parent_id":1,"depth":2,"cost":828,"operation":"HASH JOIN","cardinality":1731,"bytes":76164},{"child_number":1,"id":3,"parent_id":2,"depth":3,"cost":3,"operation":"TABLE ACCESS","options":"FULL","cardinality":6,"bytes":90,"object_owner":"NYC_DATA","object_name":"RATES","object_alias":"\"RATES\"@\"SEL$1\"","object_type":"TABLE"},{"child_number":1,"id":4,"parent_id":2,"depth":3,"cost":825,"operation":"TABLE ACCESS","options":"BY INDEX ROWID BATCHED","cardinality":2019,"bytes":58551,"object_owner":"NYC_DATA","object_name":"RIDES","object_alias":"\"RIDES\"@\"SEL$1\"","object_type":"TABLE"},{"child_number":1,"id":5,"parent_id":4,"depth":4,"cost":9,"operation":"INDEX","options":"RANGE SCAN","cardinality":2019,"bytes":0,"object_owner":"NYC_DATA","object_name":"IDX_RIDES_ON_PICKUP_DATETIME_PASSENGER_COUNT","object_alias":"\"RIDES\"@\"SEL$1\"","object_type":"INDEX"}].
How can I tune it?
Here is a video where I walk-though the whole process of evaluating the different responses to the prompt above.
Conclusion
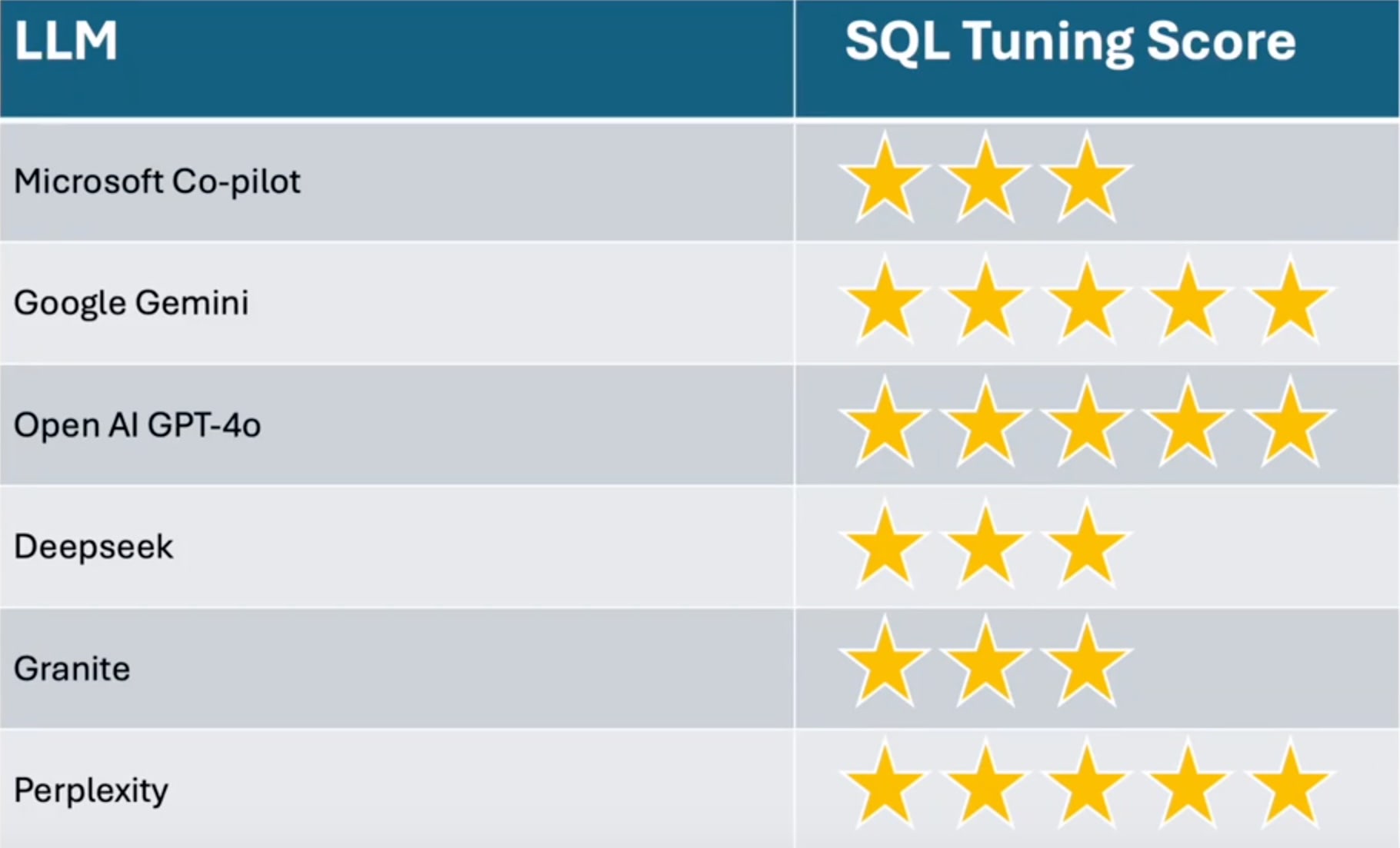
I found that 3 of the 6 gave the answer I was looking for, which in this case was the combined index on pickup_datetime and passenger_count which I had already proven would give a 99.99% reduction in response time.
I therefore awarded Google Gemini, Open AI GPT-4o and Perplexity the full 5 stars for getting the best answer and they all put it as the number 1 suggestion and provided the CREATE INDEX SQL that could be copied and run directly against the database.
The other 3 all suggested looking at indexes on various columns but didn’t suggest the combined index I was looking for and didn’t provide the CREATE INDEX SQL. While this could still be useful to point you in the right direction, I felt that it didn’t hit the mark like the other 3 so I gave Microsoft Copilot, Deepseek and Granite all 3 stars out of 5.
The use of Gen-AI LLMs in SQL tuning is an exciting development for DB professionals. While our tests highlight specific strengths and weaknesses across models, the real takeaway is that these tools can significantly augment traditional tuning approaches. As AI continues to evolve, so will the precision and reliability of these recommendations.
Remember that AI can get things wrong and so always test any suggestions in a test environment first before moving to production (which is something you should alway do anyway 😄)
Stay tuned for updates as we refine our tests and explore further into this intersection of AI and database performance.
